 会员登录
会员登录













版权归原作者所有,如有侵权,请联系我们
ChatGPT、Midjourney 和 Sora 等人工智能(AI)工具将人类天马行空的想法转化为了海量的数字内容。
然而,由于训练数据等限制,这些模型仍难以掌握现实世界的真正物理规律,也难以达到机器人在现实世界中有效自主交互所需的准确性、精确性和可靠性。
今天,强化学习大牛 Pieter Abbeel 团队研发的“机器人大脑”,则将数字数据中的内容成功带入了现实世界——
由 Abbeel 和他的学生创建的强化学习机器人平台公司 Covariant,基于自己的真实、复杂机器人数据集与海量的互联网数据,推出了一个机器人基础模型(RFM-1)。
据介绍,在识别了图像、感官数据和文本的模式后,该技术让机器人有能力处理物理世界中的突发状况。即使机器人从未见过香蕉,它也知道如何拿起香蕉。
它还能用简单的英语做出反应,就像聊天机器人一样。如果你告诉它“拿起香蕉”,它就知道是什么意思。如果你告诉它“拿起一个黄色的水果”,它也能理解。
它甚至还能生成视频,预测当它试图拿起香蕉时可能会发生什么。这些视频在仓库中没有实际用途,但它们显示了机器人对周围事物的理解。
此外,该模型不仅可以通过一般的互联网数据进行训练,还可以通过丰富的物理现实世界交互数据进行训练。
对此,Covariant 的首席执行官 Peter Chen 表示:“数字数据中的内容可以转移到现实世界中。”
模拟现实世界的“机器人大脑”
OpenAI、Midjourney 等公司开发了聊天机器人、图像生成器和其他在数字世界中运行的人工智能工具。
在这项工作中,Pieter Abbeel(总裁和首席科学家)与两位华人科学家——Rocky Duan(CTO)、Peter Chen(CEO),利用 ChatGPT 等聊天机器人背后的技术打造了可以在物理世界中导航的人工智能系统——RFM-1。

图|三位 Covariant 创始人。Rocky Duan、Pieter Abbeel 和 Peter Chen(从左到右)。
据官方博客介绍,RFM-1 可以帮助分类机器人与物理世界交互,通过视频或文本输入(用户可以像聊天机器人一样与它们对话),机器人可以“学习”如何在工厂中行动,而无需一长串指令。
RFM-1 是一个多模态任意序列(multimodal any-to-any sequence)模型,拥有 80 亿参数,可对文本、图像、视频、机器人动作和一系列数字传感器读数进行训练。
RFM-1 将所有 token 化(tokenizing)到一个共同空间,并执行自回归下一个 token 预测,从而利用其广泛的输入和输出模态实现多样化应用。
例如,它可以为场景分析任务(如分割和识别)执行图像到图像学习;可以将文本指令与图像观察相结合,生成所需的抓取动作或运动序列;也可以将场景图像与目标抓取图像配对,以视频形式预测结果,或模拟过程中可能出现的数字传感器读数。
值得关注的是,RFM-1 在物理和语言理解方面具有强大的功能。 学习世界模型是物理学模拟的未来。
RFM-1 对物理的理解来自于对视频生成的学习:通过输入初始图像和机器人动作的 token,它可以作为物理世界模型来预测未来的视频 token。
动作条件视频预测任务允许 RFM-1 学习低层次的世界模型,模拟世界每几分之一秒的变化情况。有时,预测机器人动作的高级结果更为有效。当然,由于使用了结构化多模态数据集等,RFM-1 也能提供高级世界模型。

图|RFM-1 生成的图像显示,如果从起始手提箱(左图)中挑选了特定物品(中图),它可以预测手提箱会是什么样子(右图)。
以上案例表明,RFM-1 能够理解机器人的规定动作,并能推理出这些动作是否会成功,以及垃圾箱的内容将如何变化,而这完全是通过对下一个 token 的预测来实现的。 同时,从这些世界建模任务中产生的物理理解力还能直接增强 RFM-1 的其他能力,如将图像映射到机器人行动的能力。 另外一点,有了 RFM-1,人们可以通过语言与机器人协作。 据介绍,RFM-1 能够将文本 token 作为输入进行处理,并将文本 token 作为输出进行预测,这使得任何人都可以在数分钟内(而不是数周或数月内)快速编程新的机器人行为,降低了机器人新行为编程的门槛。 例如,RFM-1 允许机器人操作员和工程师使用英语指导机器人执行特定的分拣操作。
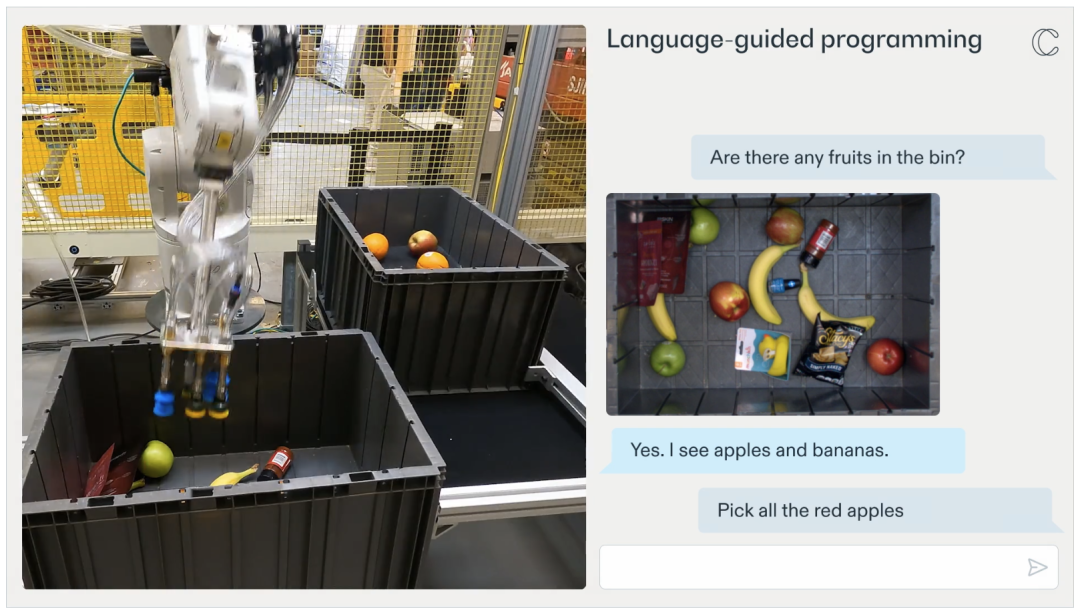
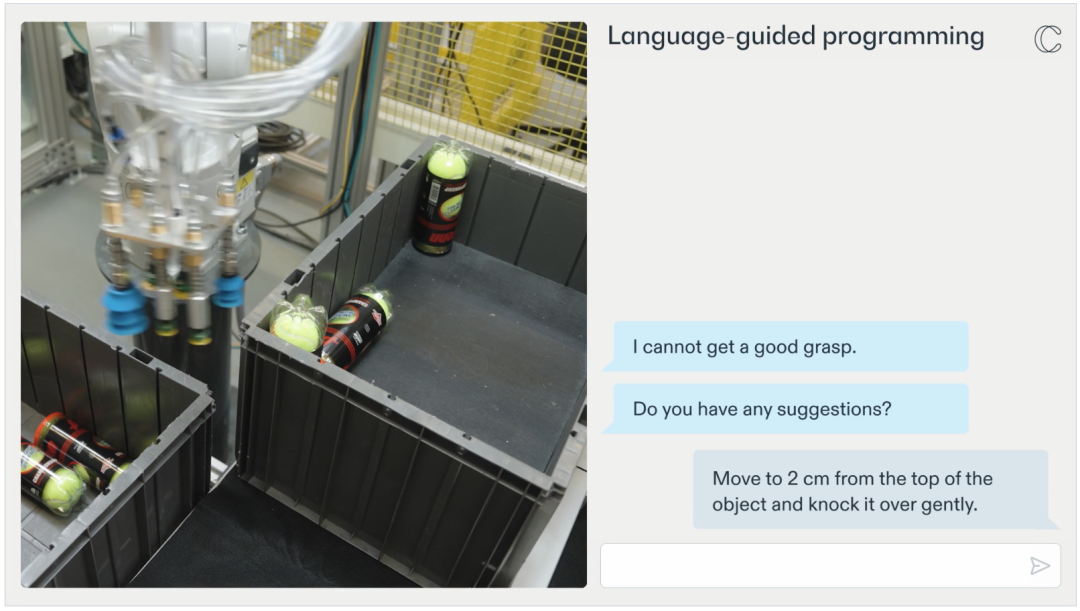
此外,RFM-1 不仅可以通过理解自然语言指令让机器人更容易完成任务,还能让机器人向人类寻求帮助。 例如,如果机器人在拾取某个物品时遇到困难,它可以将这一情况告知机器人操作员或工程师。此外,它还能提出为何在挑选物品时遇到困难。然后,操作员可以向机器人提供新的行动策略(如通过移动或撞击物体来扰动物体),从而找到更好的抓取点。在这之后,机器人就可以将这种新策略应用到未来的行动中。
开启机器人基础模型新纪元
尽管 RFM-1 在物理和语言理解方面具有强大的功能。然而,RFM-1 本身还具有一些局限性。
首先,尽管在真实生产数据上的离线测试结果很有希望,但 RFM-1 还没有部署给真实客户。Covariant 表示,他们知道如何为现有客户带来价值的第一手经验,预计将在未来数月内向他们推出 RFM-1。通过将 RFM-1 部署到生产中,他们希望收集到的数据能帮助发现 RFM-1 当前的故障模式,并加速 RFM-1 的学习。
另外,受限于模型的上下文长度,RFM-1 作为一个世界模型的运行分辨率(约 512x512 像素)和帧速率(约 5 fps)都相对较低。虽然 RFM-1 已经可以开始捕捉大型物体的变形,但还不能很好地模拟小型物体/快速运动。他们还观察到,世界模型的预测质量与可用数据量之间存在密切联系。未来,他们希望通过即将投入生产的机器人,将数据收集速度至少提高 10 倍。
最后,虽然 RFM-1 可以开始理解基本的语言命令,从而对其行为进行局部调整,但整体协调逻辑在很大程度上仍然是用 Python 和 C++ 等传统编程语言编写的。随着通过扩展数据来扩大机器人控制的粒度和任务的多样性,他们对未来人们可以使用语言来编写整个机器人程序感到兴奋,这将进一步降低部署新机器人站的门槛。
纽约大学心理学和神经科学名誉教授 Gary Marcus 认为,这种技术在仓库和其他可以接受错误的情况下可能很有用。但“在制造工厂和其他潜在危险的环境中部署这种技术会更加困难,风险也更大”。
尽管如此,Abbeel 团队依然认为,RFM-1 是机器人基础模型新纪元的开端——
通过赋予机器人类似人类的快速推理能力,RFM-1 向提供所需的自主性迈出了一大步,以解决愿意从事高度重复性和危险任务的工人日益短缺的问题,最终在未来几十年内提高生产力和经济增长。
“如果它能预测视频中的下一帧画面,就能确定正确的后续策略,” Abbeel 说。
参考链接:
https://covariant.ai/insights/introducing-rfm-1-giving-robots-human-like-reasoning-capabilities/https://www.nytimes.com/2024/03/11/technology/ai-robots-technology.html
欢迎扫码关注深i科普!
我们将定期推出
公益、免费、优惠的科普活动和科普好物!





 明德书院国学馆
明德书院国学馆










- 参加最新科普活动
- 认识科普小朋友
- 成为科学小记者



